NVIDIA Orin avanza en la IA en el edge y aumenta el liderazgo en las pruebas de MLPerf

El modelo NVIDIA Jetson AGX Orin recién lanzado elevó el nivel de la IA en el edge, para agregarse a la clasificación general en las últimas evaluaciones de inferencia de la industria.
En su debut en las evaluaciones MLPerf de la industria, NVIDIA Orin, un sistema en chip de baja potencia basado en la arquitectura NVIDIA Ampere, estableció nuevos récords en inferencia de IA. Esto elevó el nivel de rendimiento por acelerador en el edge.
En general, NVIDIA con sus socios continuó mostrando el rendimiento más alto y el ecosistema más amplio para ejecutar todas las cargas de trabajo y escenarios de machine learning en esta quinta ronda de métricas de la industria para la producción de IA.
En la IA de edge, una versión de preproducción de la NVIDIA Orin lideró cinco de las seis pruebas de rendimiento. Funcionó hasta 5 veces más rápido que la generación anterior Jetson AGX Xavier, al tiempo que ofrece en promedio una eficiencia energética 2 veces mejor.
NVIDIA Orin está disponible desde hoy en el kit de desarrollo NVIDIA Jetson AGX Orin para sistemas autónomos y de robótica. Más de 6,000 clientes, entre los que se encuentran Amazon Web Services, John Deere, Komatsu, Medtronic y Microsoft Azure , utilizan la plataforma NVIDIA Jetson para la inferencia de IA u otras tareas.
También es un componente clave de la plataforma NVIDIA Hyperion para vehículos autónomos. El fabricante de vehículos eléctricos más grande de China. BYD, es el último fabricante de automóviles en anunciar que utilizará la arquitectura DRIVE Hyperion basada en Orin para sus flotas de vehículos eléctricos automatizados de próxima generación.
Orin también es una parte clave de NVIDIA Clara Holoscan para dispositivos médicos, una plataforma que los fabricantes de sistemas y los investigadores están utilizando para desarrollar instrumentos de IA de próxima generación.
Módulo pequeño, Stack grande
Los servidores y dispositivos con las GPU de NVIDIA, incluido Jetson AGX Orin, fueron los únicos aceleradores de edge en ejecutar los seis puntos de referencia de MLPerf.
Con su SDK JetPack, Orin ejecuta la plataforma completa de IA de NVIDIA, un stack de software ya probada en el data center y el cloud. Además, está respaldada por un millón de desarrolladores que utilizan la plataforma NVIDIA Jetson.
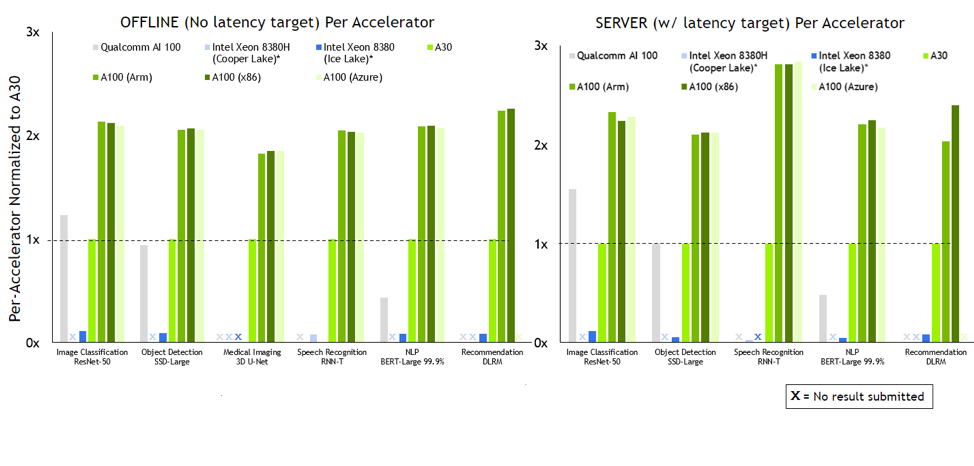
NVIDIA y sus socios continúan mostrando un rendimiento superior en todas las pruebas y escenarios en la última ronda de inferencia de MLPerf.
Las evaluaciones de MLPerf cuentan con un amplio respaldo de organizaciones como Amazon, Arm, Baidu, Facebook, Google, Harvard, Intel, Lenovo, Microsoft, NVIDIA, Stanford y la Universidad de Toronto.
Más Socios y Propuestas
La plataforma de IA de NVIDIA nuevamente atrajo el mayor número de propuestas de MLPerf procedentes del ecosistema más amplio de socios.
Azure obtuvo un excelente resultado después de su debut en diciembre en las pruebas de entrenamiento MLPerf, en esta ronda sobre inferencia de IA. En ambos casos utilizó las GPU NVIDIA A100 Tensor Core. La instancia ND96amsr_A100_v4 de Azure igualó las presentaciones de ocho GPU con el rendimiento más alto en casi todas las pruebas de inferencia, lo que demuestra la potencia disponible en el cloud público.
Los fabricantes de sistemas ASUS y H3C hicieron su debut con MLPerf en esta ronda con presentaciones que utilizaron la plataforma de IA de NVIDIA. Se unieron a los fabricantes de sistemas Dell Technologies, Fujitsu, GIGABYTE, Inspur, Nettrix y Supermicro que presentaron los resultados de más de dos docenas de Sistemas Certificados por NVIDIA.
Por Qué Es Importante MLPerf
Nuestros socios participan en MLPerf porque saben que es una herramienta valiosa para los clientes que evalúan plataformas y proveedores de IA.
Las diversas pruebas de MLPerf abarcan las cargas de trabajo y los escenarios de IA más populares de la actualidad. Esto les da a los usuarios la confianza de que las evaluaciones reflejarán el rendimiento que pueden esperar en todo el espectro de sus trabajos.
El Software Brilla
Todo el software que utilizamos para nuestras pruebas está disponible en el repositorio de MLPerf.
Dos componentes clave que permitieron obtener los resultados de inferencia – NVIDIA TensorRT para optimizar modelos de IA y el Servidor de Inferencia NVIDIA Triton para implementarlos de manera eficiente- están disponibles de forma gratuita en NGC, el catálogo de software optimizado para GPU.
Las organizaciones de todo el mundo están adoptando Triton, incluidos los proveedores de servicios de cloud como Amazon y Microsoft.
Desde Nvidia se incorporan continuamente todas las optimizaciones en contenedores disponibles en NGC. De esta manera, cada usuario puede comenzar a producir IA con un rendimiento líder.




